
That was a splice, I never said that!
If you were thinking artists were going to be the only ones screwed over by the AI future, well, you were wrong. Because Microsoft has an AI that can learn to imitate anyone’s voice* from as little as a 3-second clip of them talking.
*With certain caveats discussed below
The program in question is called VALL-E, which Microsoft’s researchers trained on over 60,000 hours of audiobook narration from over 7,000 readers. This essentially makes it the largest such program yet, many times large than the models of most text-to-speech programs.
Microsoft published a website with samples of the results. And they’re frankly uncanny. It can not only duplicate the sound and inflections of a human voice to make it say anything that is desired, it can also imitate emotion in a voice. Even different speaking styles aren’t beyond it.
Human Speaker
VALL-E
Human Speaker
VALL-E
While voice cloning is far from now, VALL-E is able to do it with far less input material than most other programs. And Microsoft realizes that the possibility to use it for wrong is incredibly high. From the paper published by the researchers:
Since VALL-E could synthesize speech that maintains speaker identity, it may carry potential risks in misuse of the model, such as spoofing voice identification or impersonating a specific speaker.
…that said, the researchers are confident that there will be a way to create a program that could “discriminate whether an audio clip was synthesized by VALL-E.”
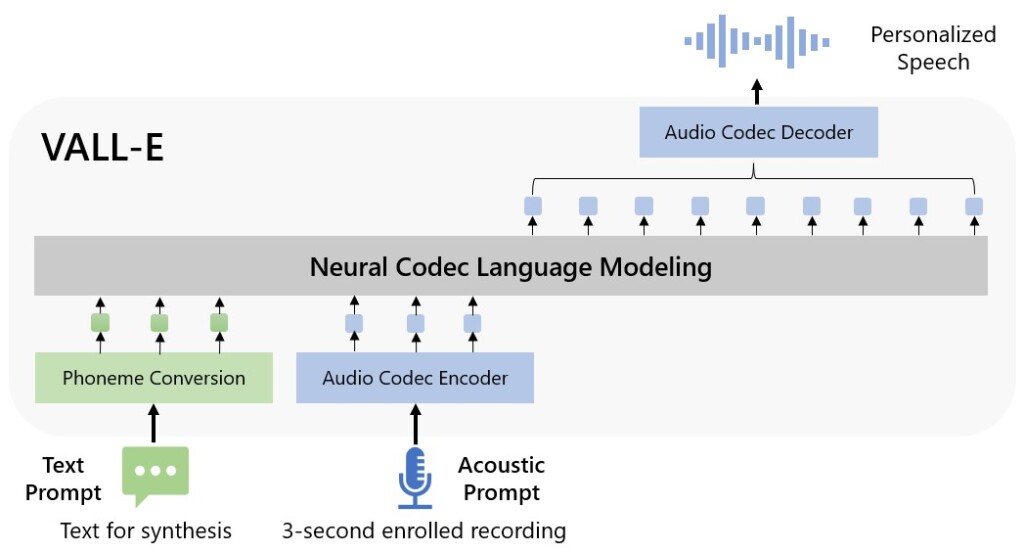
VALL-E interprets speech as “discrete tokens,” which it then uses to speak with different text from the source. Once again per the paper:
VALL-E generates the corresponding acoustic tokens conditioned on the acoustic tokens of the 3-second enrolled recording. Finally, the generated acoustic tokens are used to synthesize the final waveform with the corresponding neural codec decoder.
You might remember that asterisk way up in the first paragraph, though. Apparently, VALL-E has trouble with its intended purpose: sometimes, word sound off, garbled or robotic. It also has some trouble with accents.
Human Speaker:
VALL-E:
Even if we use 60K hours of data for training, it still cannot cover everyone’s voice, especially accent speakers. Moreover, the diversity of speaking styles is not enough, as LibriLight (the audio VALL-E was trained on) is an audiobook dataset, in which most utterances are in reading style.
That said, there’s nothing there that time and input can’t improve. As might be obvious, however, Microsoft hasn’t released VALL-E publicly; primarily, to avoid misuse.
Source: PC Mag